Introducing the Cloud-Optimized Geospatial Formats Guide
TL;DR: We’re excited to introduce the Cloud-Optimized Geospatial Formats Guide to help you navigate the ever-expanding universe of cloud-native geospatial technologies. Many thanks to NASA’s Interagency Advanced Concepts and Implementation Team (IMPACT) and Development Seed for their leadership in creating this guide and opening up to the community.
Last week, NASA announced that NASA’s Level-1 and Atmosphere Archive and Distribution System Distributed Active Archive Center (LAADS DAAC) has moved all of its storage to the cloud. According to a lead on the project, this represents 5.7 petabytes of data across 73 million data files. What’s more, the project was completed almost a year ahead of schedule. This is just one anecdote of many that shows how quickly a lot of geospatial data is quickly moving to the cloud.
This rapid migration to the cloud has created a movement toward “cloud-native” geospatial applications that take advantage of the scalability and performance of cloud infrastructure. Fueling these applications are new cloud-optimized geospatial data formats that are scalable, accessible, and flexible enough to be used in a wide array of applications.
To help you navigate the expanding universe of cloud-optimized geospatial data formats, we’re excited to introduce the Cloud-Optimized Geospatial Formats Guide.
Led by NASA’s Interagency Advanced Concepts and Implementation Team (IMPACT) and Development Seed, the Cloud-Native Geospatial Foundation is hosting this community-powered guide to give newcomers and experts a single place to learn about best practices for working with data in the cloud. This guide is managed on GitHub and openly-licensed. We encourage community contributions to keep it up-to-date and valuable for all.
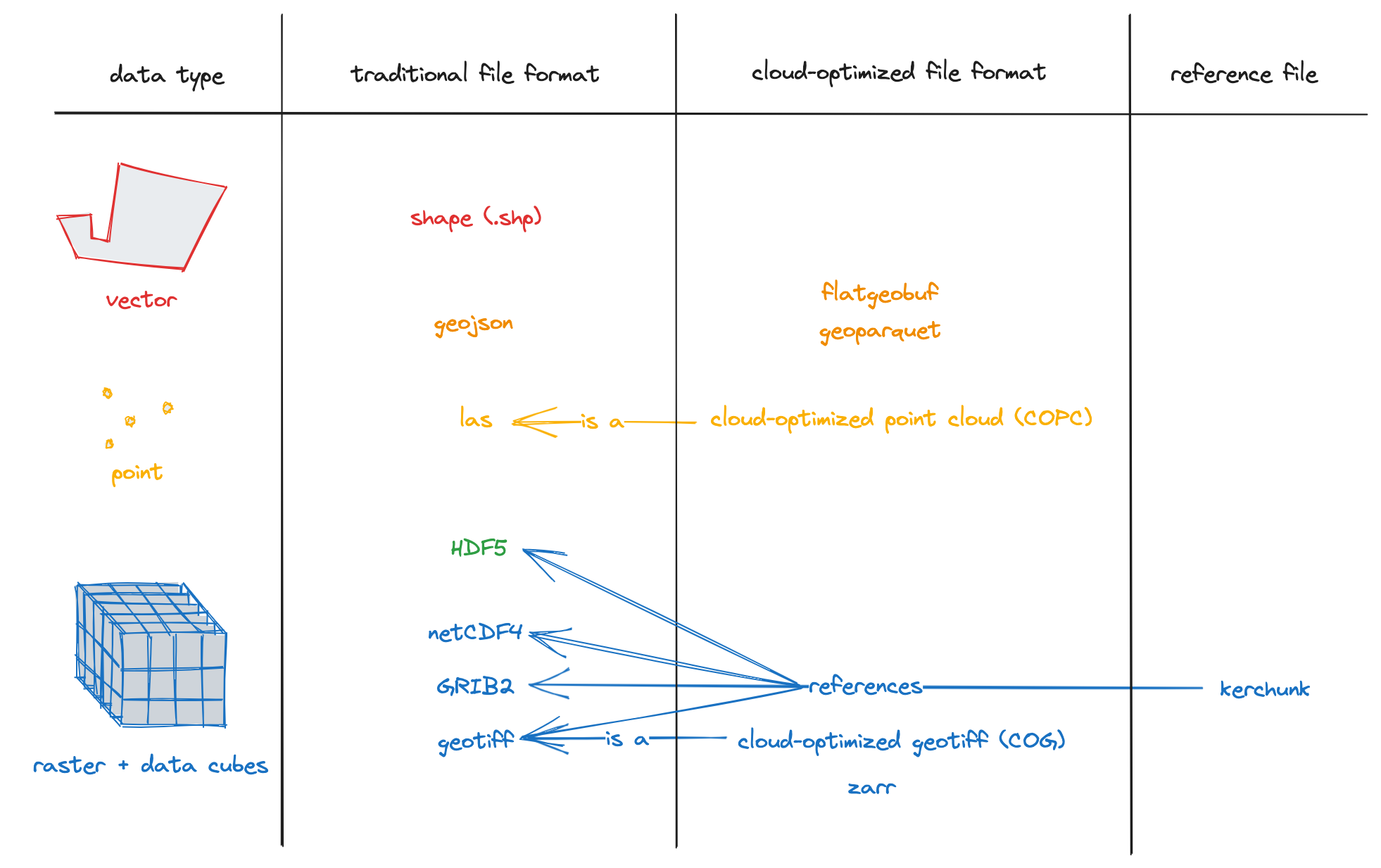
Cloud-Optimized Geospatial Formats.
Here is what to expect in the guide:
- An overview of cloud-optimized data and why you should consider it.
- A glossary of terms to help demystify the language used when discussing cloud-optimized data and get us all on the same page.
- Primers for the most common cloud-optimized formats and some newer formats gaining traction.
- Vector, raster, datacubes, and point cloud data formats are covered!
- Notebooks with examples that you can try yourself.
- Links to lots of other resources to further enhance your understanding.
- Coming soon: Advanced topics!
Advanced topics will explore visualizing various data types (e.g., Zarr, GeoParquet) in browsers and Jupyter notebooks, mastering HTTP range requests, assessing chunking and compression configurations, and benchmarking performance for different use cases, such as time series generation vs spatial aggregations. Join the conversation in the discussion board to connect with a community of like-minded individuals, share insights and seek help.
A sincere thank you to our dedicated authors, Aimee Barciauskas, Alex Mandel, Kyle Barron, and Zac Deziel. Thank you also to contributors of the Overview Slides: Vincent Sarago, Chris Holmes, Patrick Quinn, Matt Hanson, and Ryan Abernathey. Their expertise and commitment have been instrumental in bringing the guide to life.
Our blog is open source. You can suggest edits on GitHub.