The GeoParquet Ecosystem at 1.0.0
One of the things I’m most proud of about GeoParquet 1.0.0 is how robust the ecosystem already is. For the 1.0.0 announcement, I started to write up all the cool libraries and tools supporting GeoParquet, and the awesome data providers who are already providing interesting data in the spec. But I realized it would at least double the length of the blog post to do it justice, so I decided to save it for its own post.
The libraries
The core of a great ecosystem is always the libraries, as most tools shouldn’t be writing their own special ways to talk to different formats – they should be able to leverage a well-optimized library so they can spend their time on other things. The first tool to support GeoParquet, before it was even called GeoParquet, was the great GeoPandas library. They added methods to read and write Parquet, and then Joris Van den Bossche and Dewey Dunnington started the process of standardizing the geospatial parquet format as part of GeoArrow as they explored cross-library reading and writing. Joris wrote the GeoPandas Parquet methods, and Dewey worked in R, working on the GeoArrow R library (there’s also another R library called sfarrow). Their initial work became the core of the GeoParquet spec, with a big thanks to Tom Augspurger for joining their community with the OGC-centered one where I started. We decided to use the OGC repo that I was working in for the GeoParquet spec, and to keep the GeoArrow spec repository focused on defining Geospatial interoperability in Arrow. Arrow and Parquet are intimately linked, and defining GeoParquet was much more straightforward, so we all agreed to focus on that first.
The next two libraries to come were sponsored by Planet. Even Rouault added drivers for GeoParquet and GeoArrow to GDAL/OGR, and while he was at it created the Column-Oriented Read API for Vector Layers. The new API enables OGR to ‘retrieve batches of features with a column-oriented memory layout’, which greatly speeds things up for reading any columnar format. And Tim Schaub started GPQ, a Go library for working with GeoParquet, initially enabling conversion of GeoJSON to and from GeoParquet, and providing validation and description. He also packaged it up into a webapp with WASM, enabling online conversion to and from GeoParquet & GeoJSON. Kyle Barron also started working extensively in Rust, using it with WASM as well for browser-based tooling. Bert Temme also added a DotNet library. For Python users who are working in row-based paradigms, there is also support in Fiona, which is great to see. And there’s a GeoParquet.jl for those working in Julia.
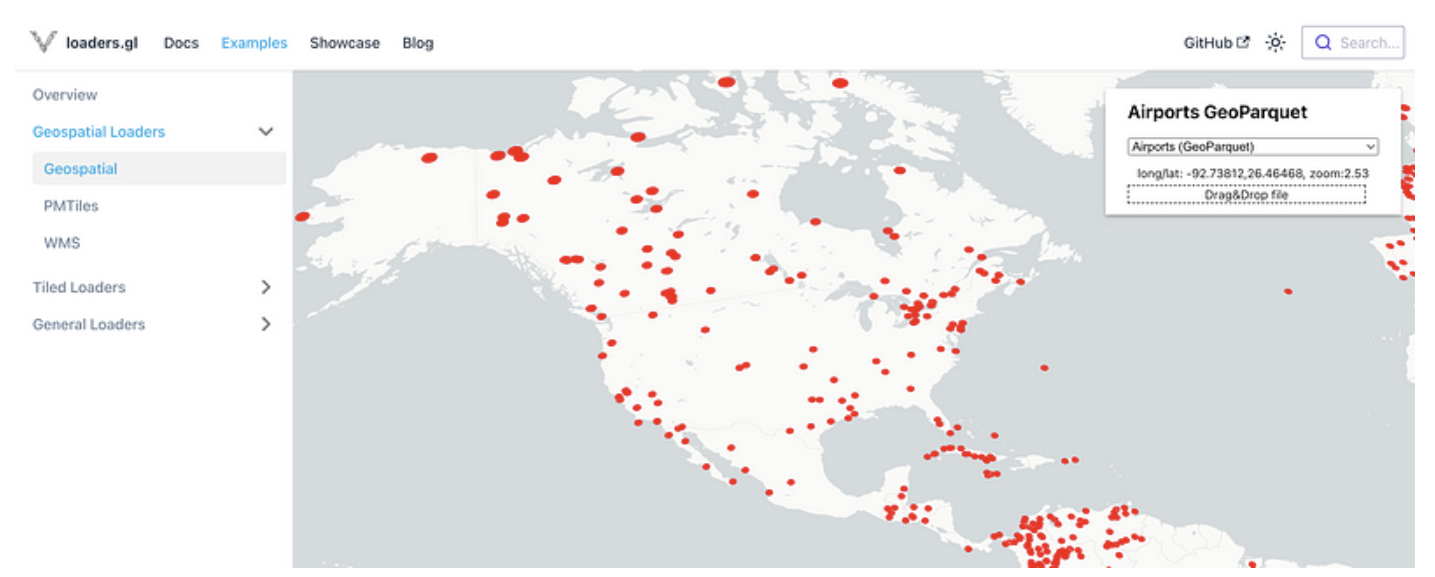
And the most recent library to support GeoParquet is a pure javascript one in loaders.gl, thanks to Ib Green. It will likely not support the full Parquet spec as well as using something like GPQ in WASM, since there is not a complete Javascript Parquet library. But it will be the most portable and easy to distribute option, so is a great addition.
The one library I’m now still hoping for is a Java one. I’m hoping someone in the GeoTools & GeoServer community takes up the call and writes a plugin, as that one shouldn’t be too difficult. And of course, we’d love libraries in every single language, so if you have a new favorite language and want what is likely a fairly straightforward programming project that will likely see some widespread open source use, then go for it! There are pretty good Parquet readers in many languages, and GeoParquet is a pretty minimal spec.
The Tools
This is a much wider category, and I’m sure I’ll miss some. I’m loosely defining it as something a user interacts with directly, instead of just using a programming language (yes, an imperfect definition, but if you want to define it you can write your own blog post ;) ).
Command-line Tools
I count command-line interfaces as tools, which means I’ll need to repeat two of the libraries above:
- OGR/GDAL– is obviously the king of the geospatial command-lines, and having GeoParquet support means that any master of its command-line, especially ogr2ogr, can easily get any file into and out of GeoParquet.
- GPQ–has a great command-line interface enabling conversion from GeoJSON and ‘compatible’ Parquet to GeoParquet. It’s also got one of the easiest validators to work with, providing a full accounting of each of the checks:
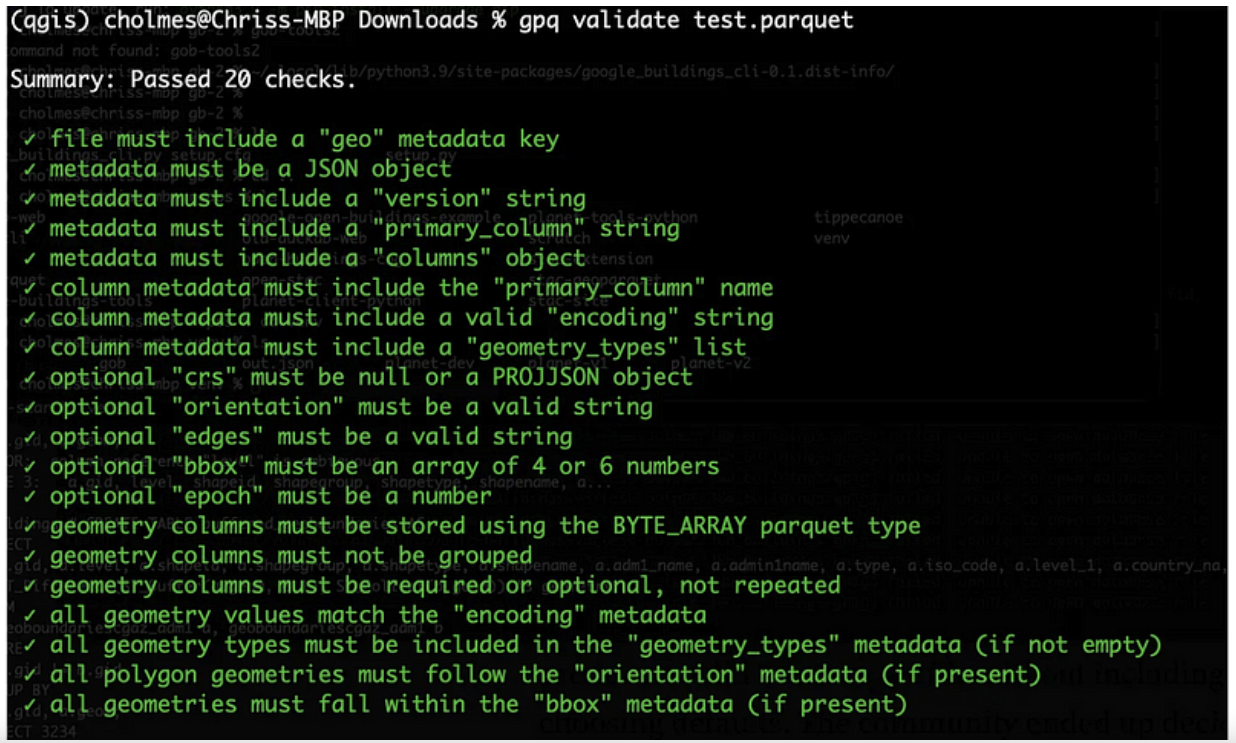
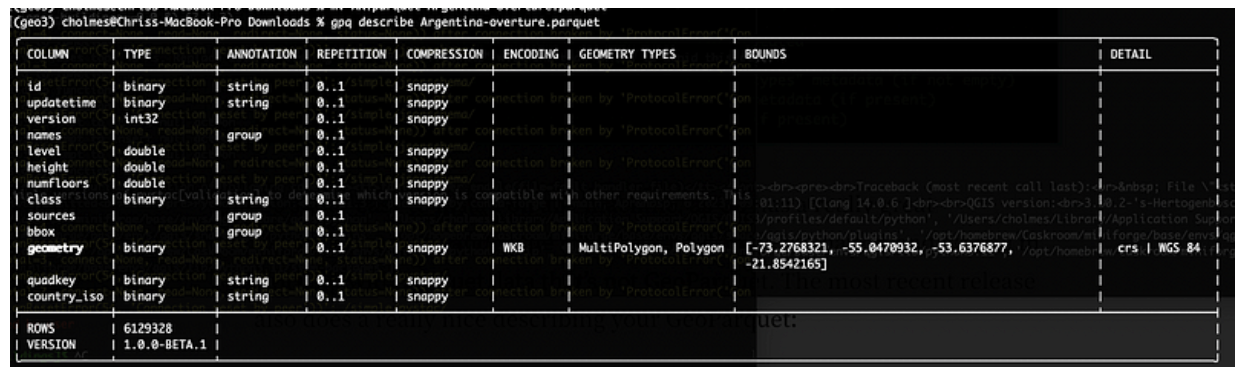
It’s super easy to install on any machine, as Go has a really great distribution story, and is the main tool I use to do validation and when I’m working with Parquet data that’s not GeoParquet. The most recent release also does a really nice job description of your GeoParquet:
Desktop
For traditional GIS workflows, QGIS uses GDAL/OGR, so can easily read GeoParquet if the right version of GDAL/OGR is there.
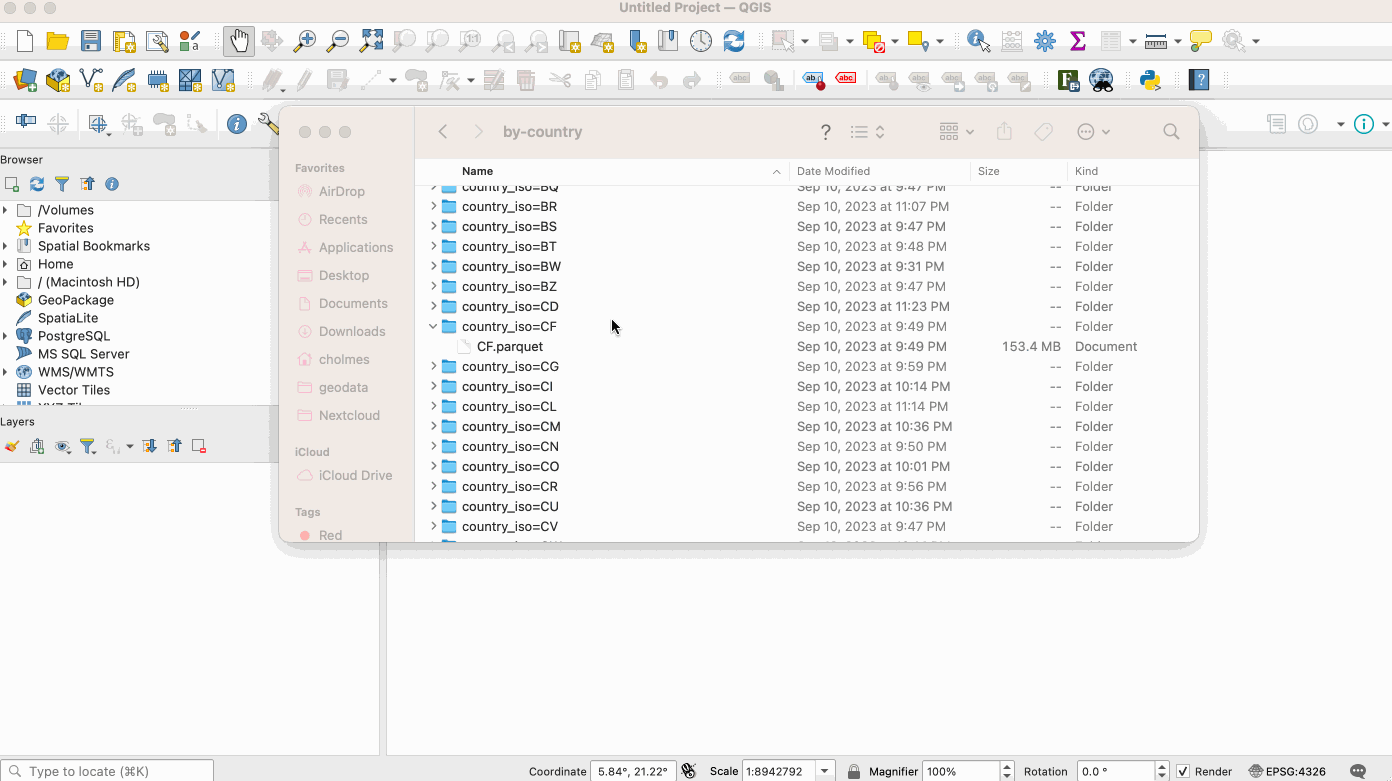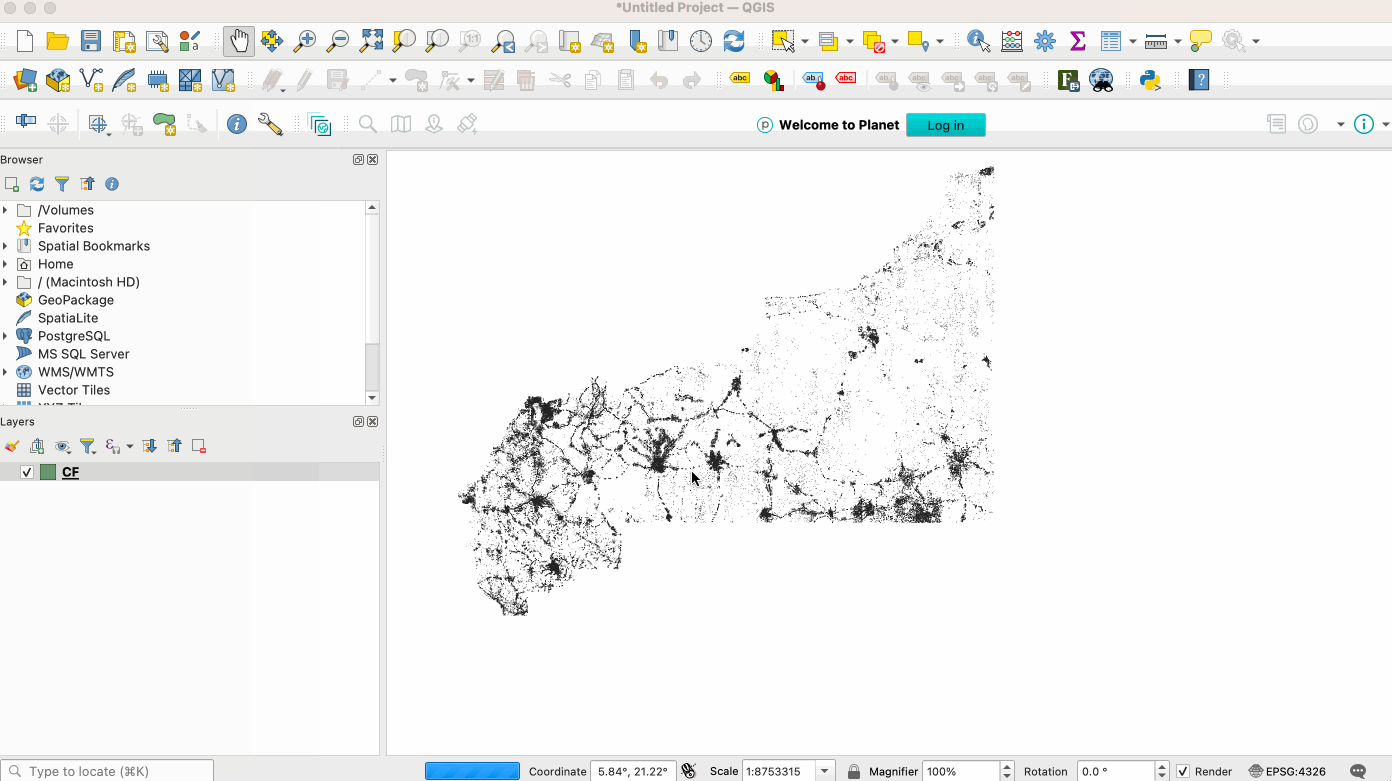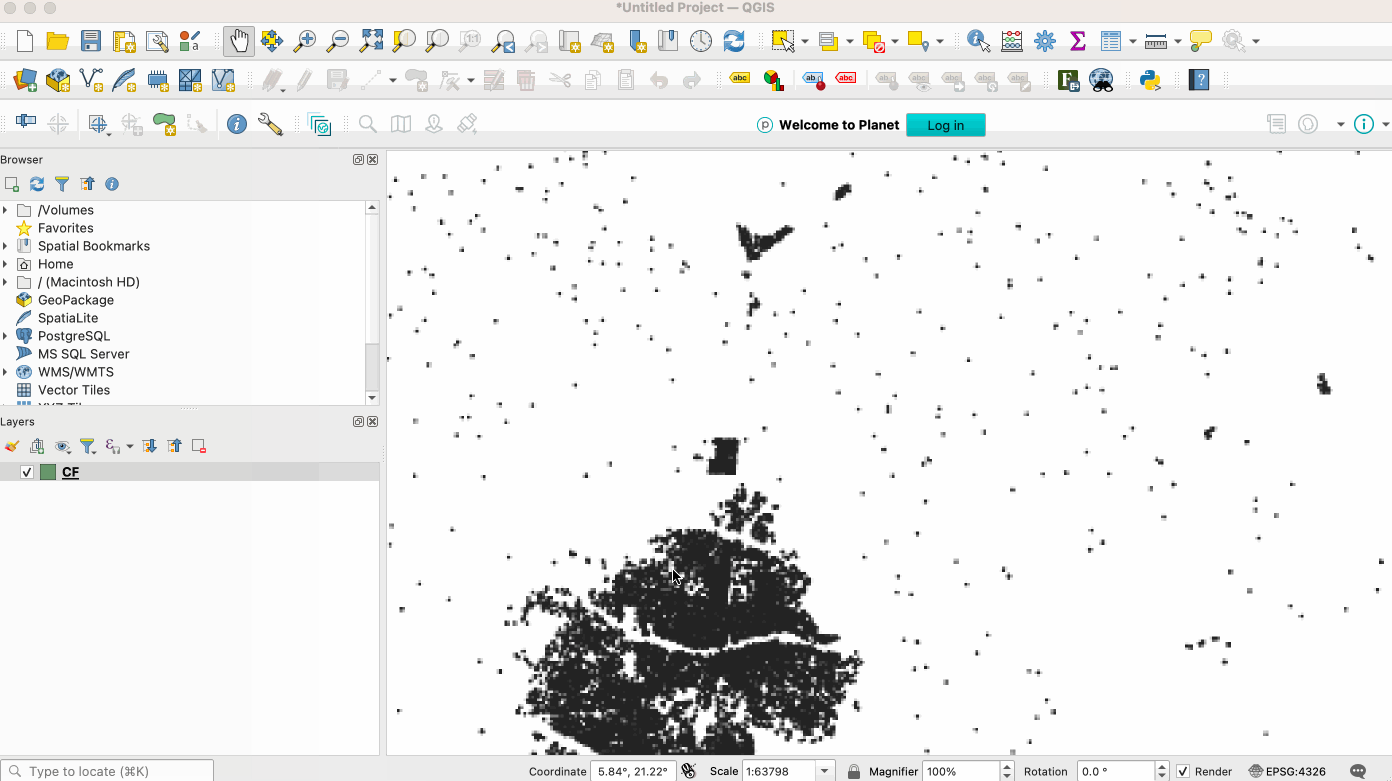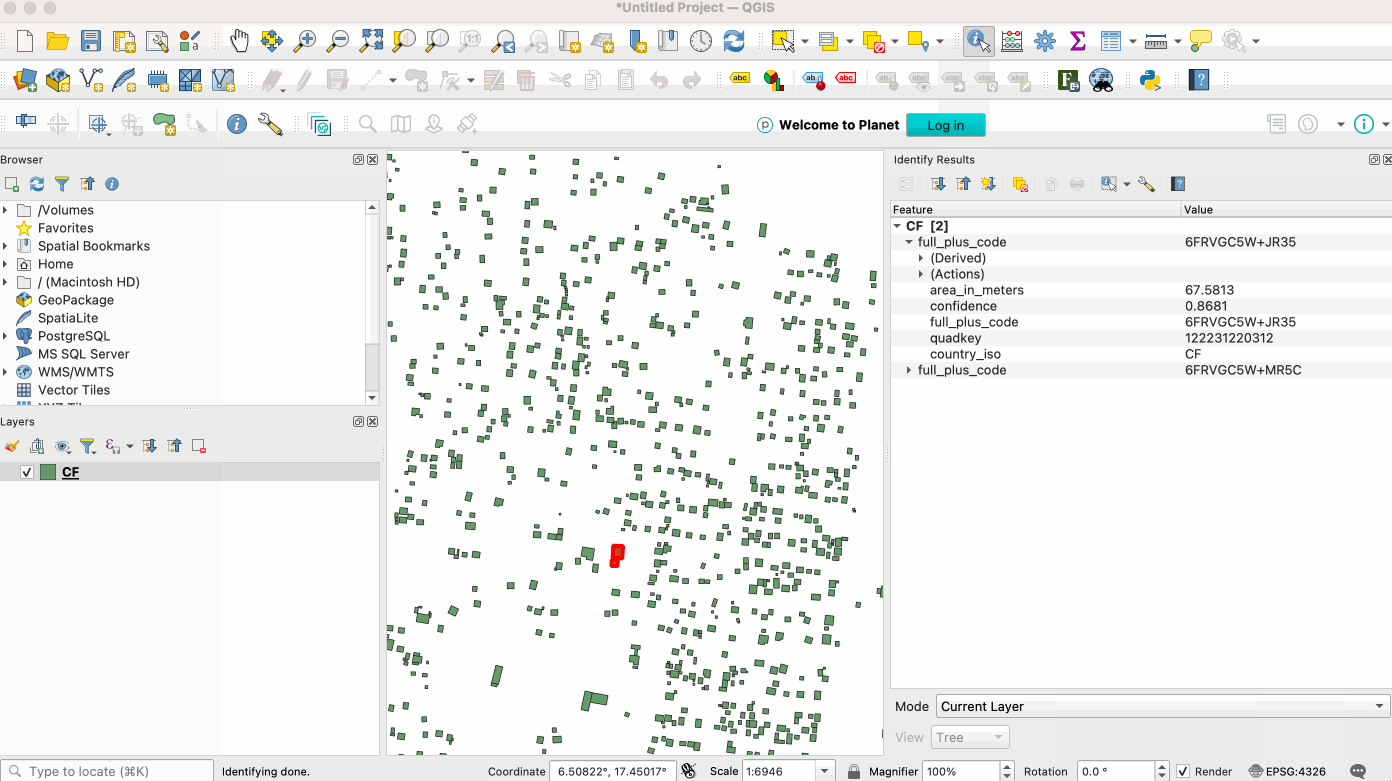
For Windows this works out of the box using the main QGIS installer (OSGeo4W). Unfortunately the Mac OS/X installer doesn’t yet include the right dependencies, but if you’re on a Mac you can install QGIS with conda. Just install conda and then run conda install qgis libgdal-arrow-parquet, then start QGIS from the terminal (just type ‘qgis’). This is a bit annoying, but it’s currently how I always use QGIS, and isn’t bad at all. For Linux Conda works well, just install QGIS with the same command to be sure the right GDAL libraries for GeoParquet are there. The main QGIS installer might also work (hopefully someone can confirm this).
Safe Software’s FME also added GeoParquet support in version 2023.1. It’s probably the best tool on the market for transforming data, so it’s great to see it supported there.
Web-based Tools
There’s a ton of potential for GeoParquet on the web, and it’s been great to see many of the coolest web tools embracing it. The first to support GeoParquet was Scribble Maps. You can easily drag a GeoParquet on it and everything ‘just works’, and you can also export any layer as GeoParquet.
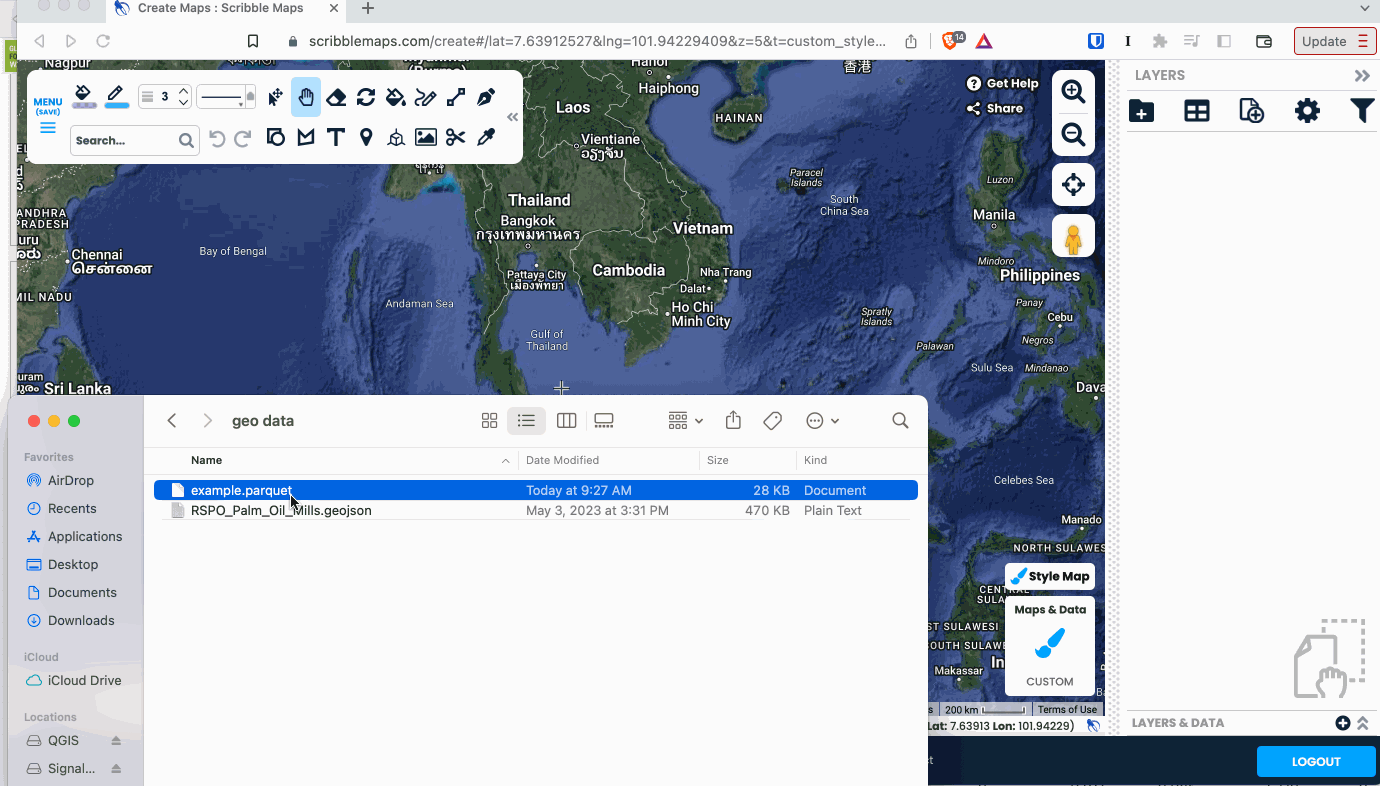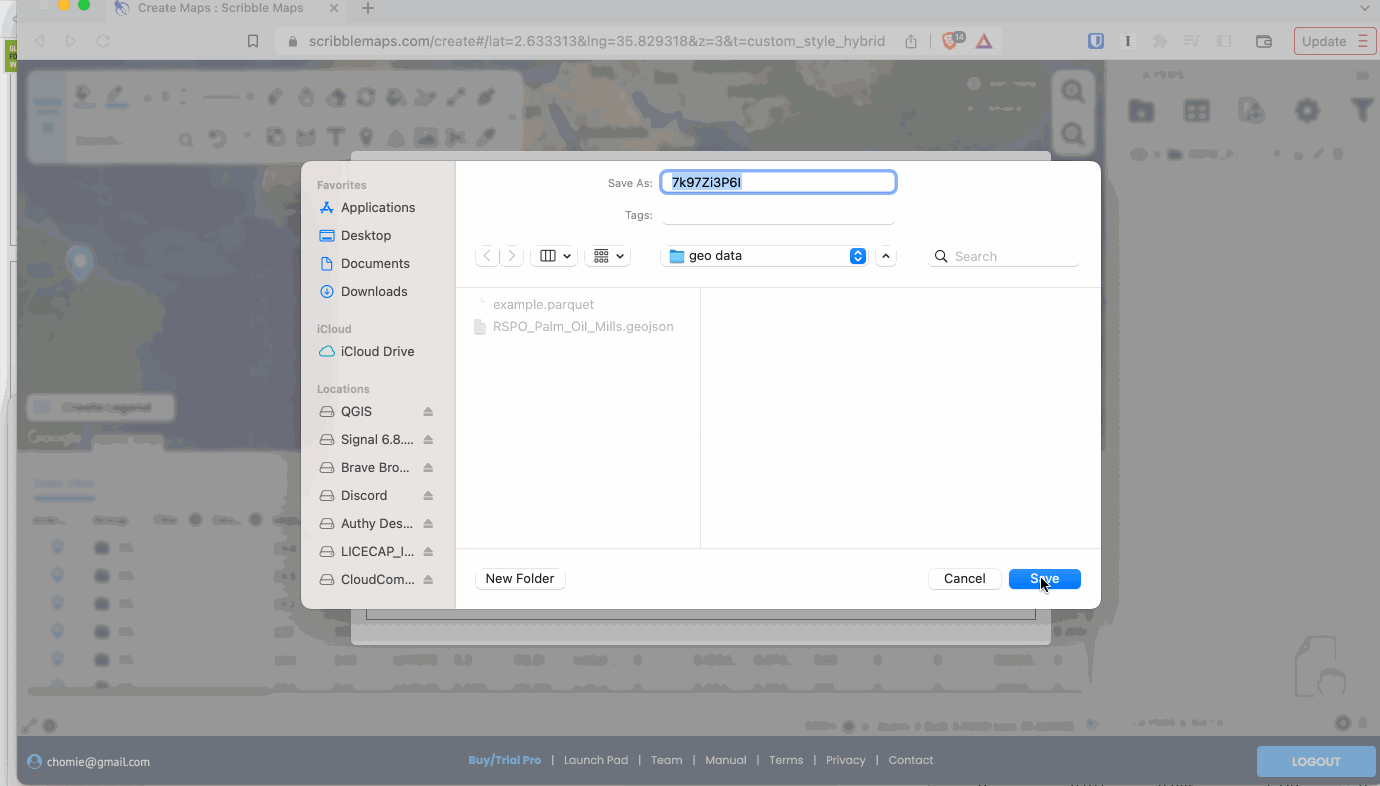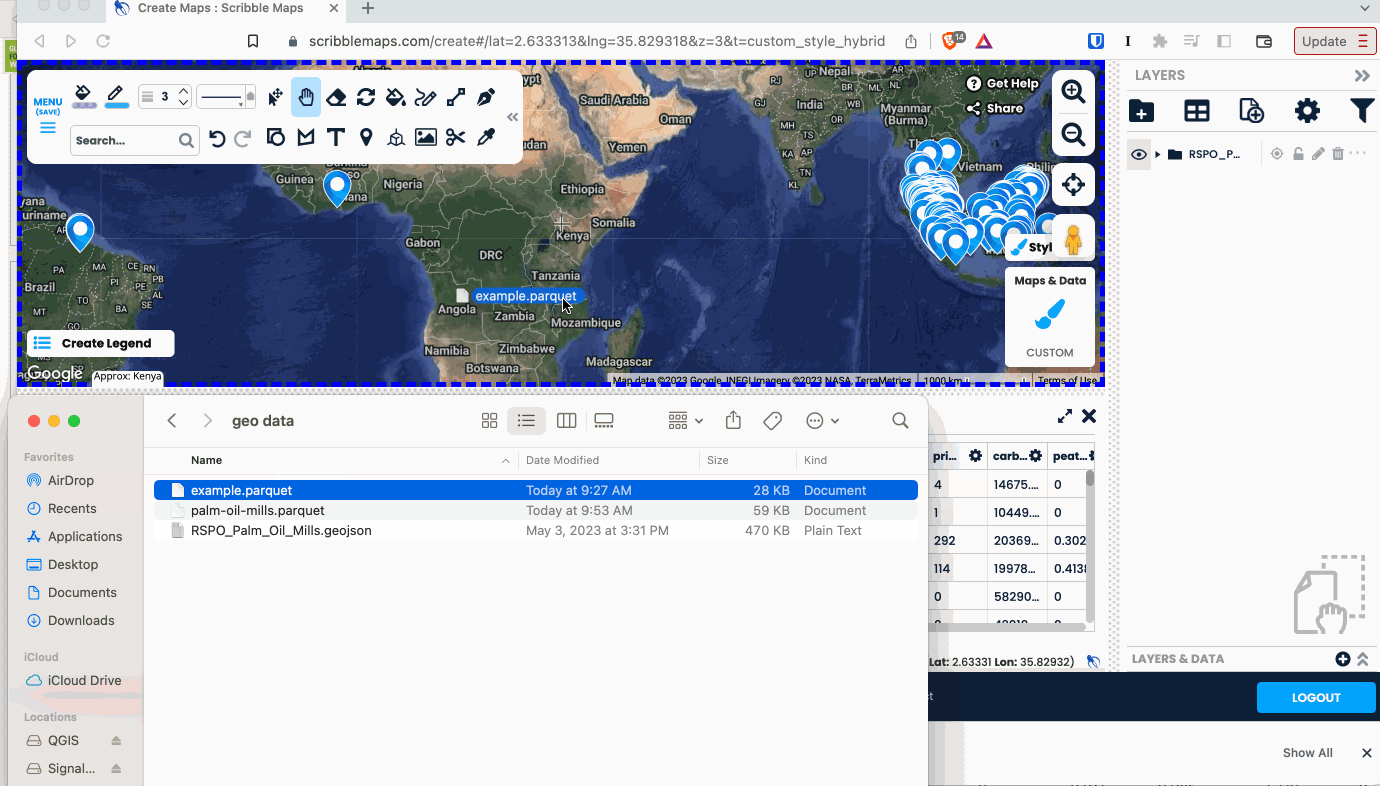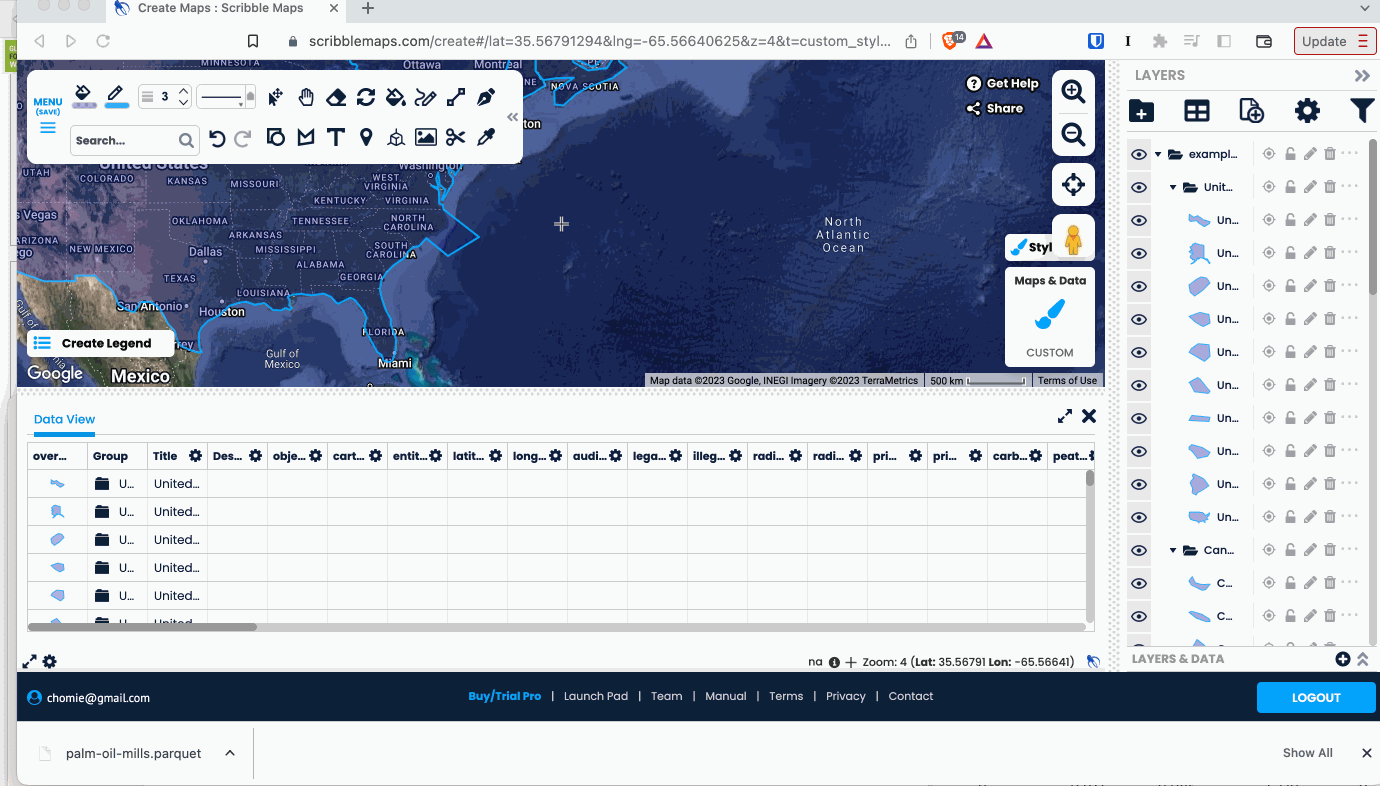
It’s a great tool that’s been adding tons of great functionality recently, so definitely check it out. They use a WASM distribution of GPQ under the hood, showing off how capable the browser is becoming.
You can also make use of a web-based GeoJSON converter, available on geoparquet.org, that’s also powered by GPQ.
CARTO, my long-time favorite web-based analysis platform, added GeoParquet support recently. They’ve been one of the biggest supportors of GeoParquet, with Alberto Asuero helping with core spec work and Javier de la Torre leading lots of evangelizing of GeoParquet. You can easily import GeoParquet, and they’re starting to support export as well.
There’s also been a lot of awesome experimental work that’s not quite ‘tools’ yet, but shows off the potential of GeoParquet on the web. Kyle Barron has been doing a lot with Rust and WASM, really pushing the edge of what’s possible in the browser. Not all his work is actually not using GeoParquet directly, but showing just how far the browser can go in displaying massive amounts of geospatial data. Under the hood he uses a lot of Arrow, which is closely related to Parquet, and GeoParquet will be the preferred way to get data into his tools. You can check out his awesome observable notebooks and learn a ton about the bleeding edge of geospatial data in the browser:
- GeoParquet on the Web
- GeoArrow and GeoParquet in deck.gl
- Prototyping GeoRust + GeoArrow in WebAssembly
There’s also cool experiments like Overture Maps Downloader, which uses DuckDB in Web Assembly to interact with Overture Map GeoParquet files up on source.coop. You can check out the source code on github.
Also any web tool that uses loaders.gl will likely soon support Geoparquet as they update to the latest release. Chief among those are deck.gl and cesium, so hopefully we can fully add both to the list soon.
Converters
There’s also a couple nice little tools to help with specific conversions of STAC. The BigQuery converter was built by the Carto team, to help get valid GeoParquet out of BigQuery. Our hope is that BigQuery supports GeoParquet directly before too long (if you’re a BigQuery user please tell your Google account manager you’re interested in supporting it, or let me know and I can connect you with the PM), but in the meantime it’s a great little tool. There’s also a tool to convert any STAC catalog to GeoParquet, called stac-geoparquet. It powers Planetary Computer’s GeoParquet versions of their STAC Collections, and is evolving to be less tied to Azure.
Frameworks & Data Engines
A few of the above things (FME, Carto) could reasonbly be called frameworks, and I’m using this category as a bit of a catchall. Apache Sedona was an early adopter and promoter of GeoParquet, and you can do incredible big data processing of any spatial data with it. Wherobots is a company formed by core contributors to Sedona, and they’re working on some exciting stuff on top of it, and have been great supportors of the ecosystem. Esri also has support for GeoParquet in their ArcGIS GeoAnalytics Engine, which lets Esri users tap into big data compute engines. Seer AI is also a new, powerful platform, and they’re using GeoParquet at the core, and it’s easy to import and export data. The other tool worth mentioning is DuckDB. I recently wrote up my excitement for it. It doesn’t actually yet directly support GeoParquet, but their Parquet and Geo support are both so good that it’s quite easy to do. I’m optimistic they’ll support GeoParquet for real soon.
The Data
I had some ambitious goals to get a ton of data into GeoParquet before 1.0.0, that we didn’t quite meet. But in the few weeks past 1.0 it’s been accelerating quickly, and I think we’re just about there.
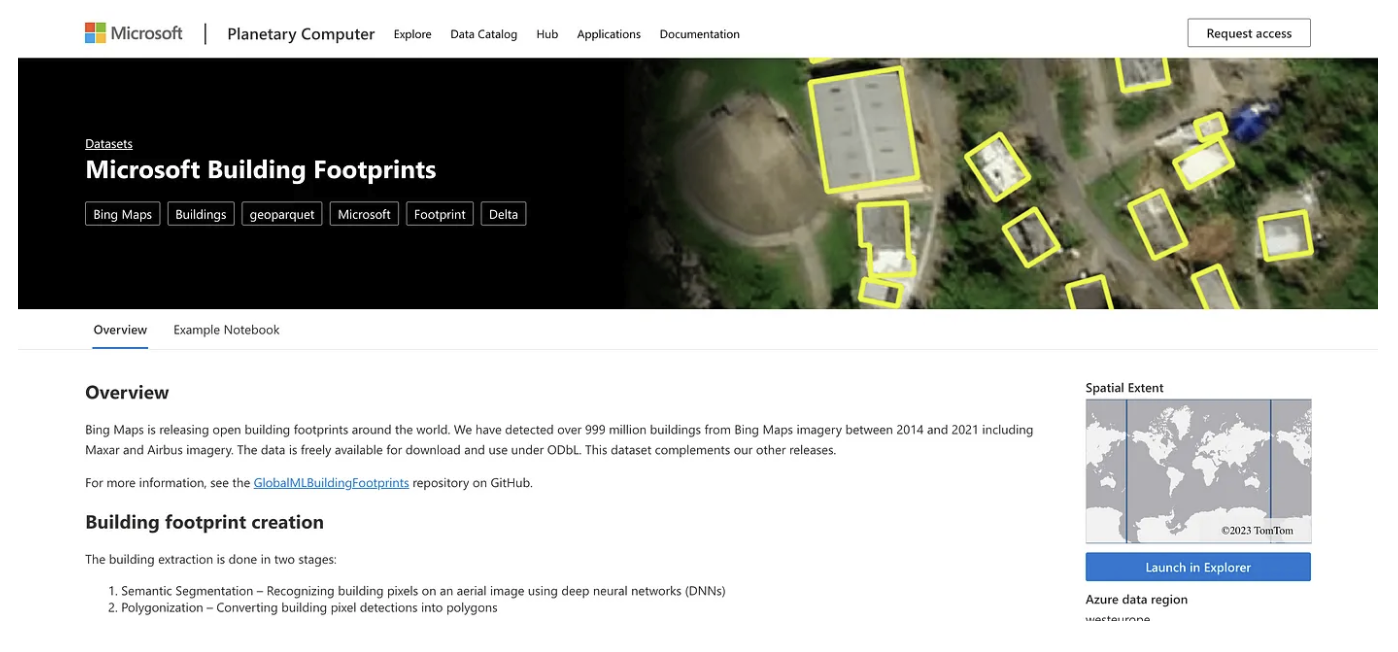
One goal was ‘data providers’, the number of different organizations providing at least some sort of data in GeoParquet. Microsoft has been incredible on this, producing GeoParquet versions of all their STAC catalogs, and also really showing off the power of partitioned GeoParquet with their building footprints dataset.
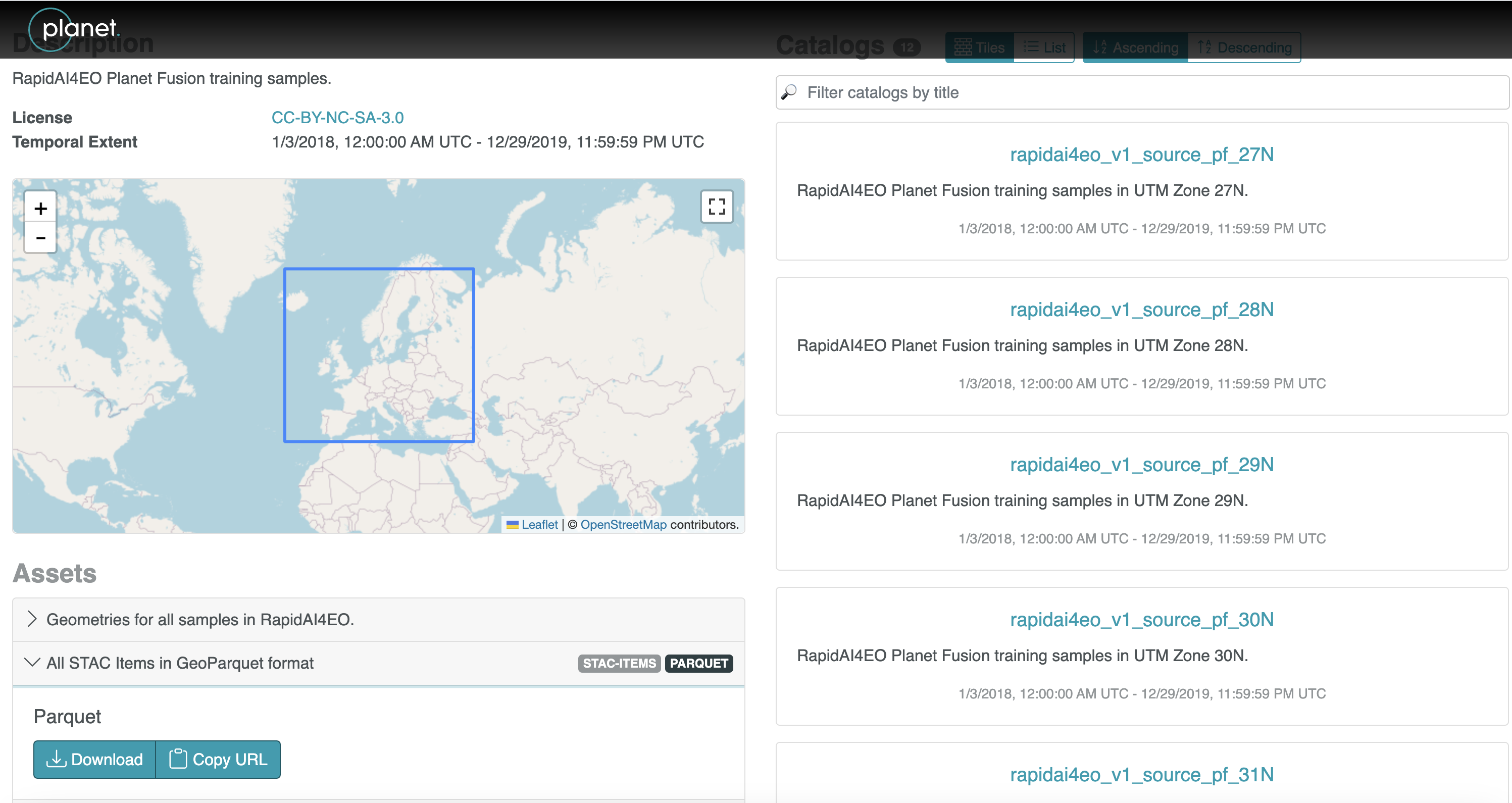
The second producer to put data up as GeoParquet was Planet, converting the RapidAI4EO STAC dataset into GeoParquet, and Maxar also converted their Open Data STAC to GeoParquet.
But it’s not just all STAC! I’m most interested in more non-STAC datasets, and they are starting to emerge. Carto has started making their Data Observatory available in GeoParquet, and there are tons of great datasets (demographics, environmental, points of interest, human mobility, financial, and more) there. Not all are fully available yet, but if you’re a Data Observatory user and want particular datasets as Geoparquet they can likely prioritize it.
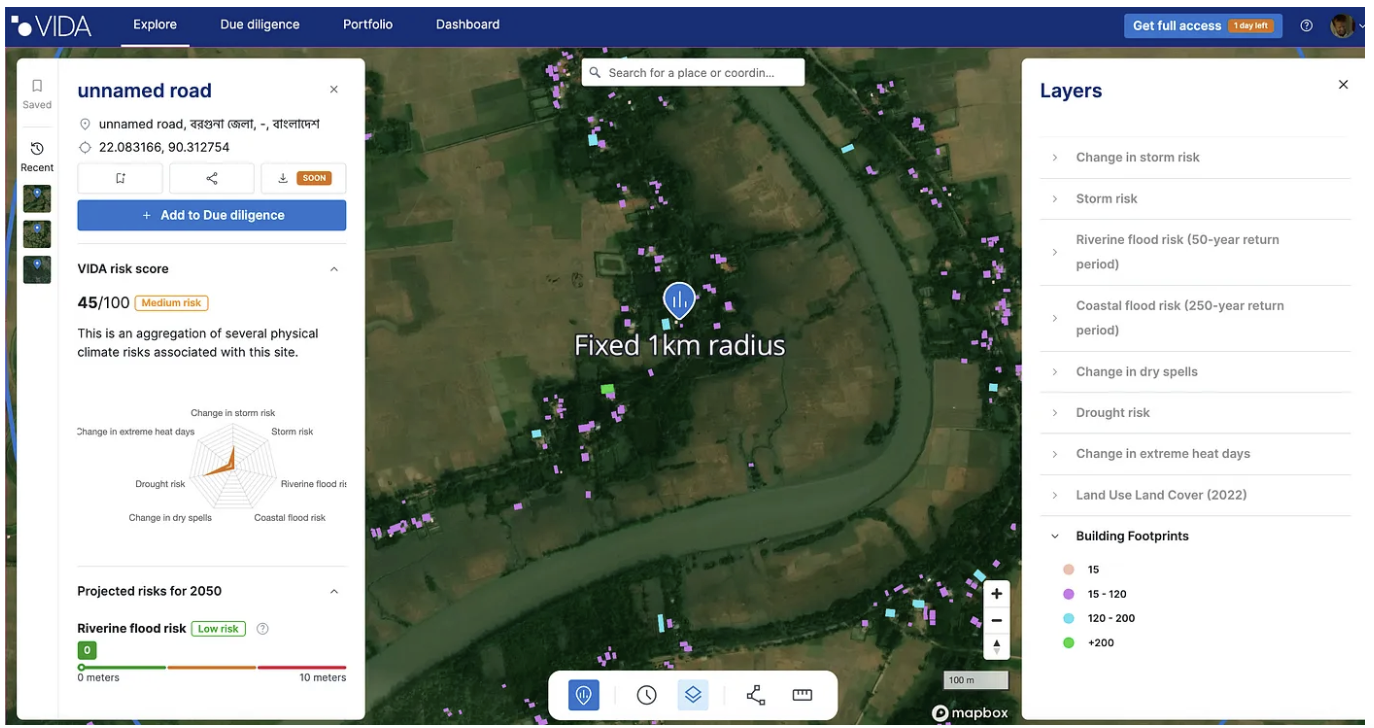
The Ordnance Survey, UK’s national mapping agency, has also put their National Geographic Database – Boundaries Collection in GeoParquet, with a number of great data layers. And one of the datasets I’ve been most excited about in general was released as GeoParquet by VIDA, a cool company in the Netherlands working on climate risk. They combined the Google Open Buildings dataset with the Microsoft Building Footprint open data into a single dataset, it’s available on Source and you can read about it in their blog post.
It’s got over 2.5 billion rows in almost 200 gigabytes of data, partitioned into individual country GeoParquet files. There’s also a nice version of the ESA World Cereals dataset created by Streambatch, they wrote up a great tutorial on converting it to GeoParquet, and the final data file is available on Source Cooperative.

One thing you’ll notice if you follow many of these links is that most are hosted on Source Cooperative, a new initiative from Radiant Earth. You can find lots of cloud-native geospatial data there, and it’s emerging as a central location for open data. I’ve also just been converting data into GeoParquet and hosting it there, you can get the Google Building Footprints, the Overture data as GeoParquet (it was released as Parquet but not GeoParquet), EuroCrops and the NYC Taxi Zones from TLC Trip Record Data. I’m hoping to work on converting many more datasets to GeoParquet, and if anyone else wants to join me in that mission I can get you an invite to Source Cooperative if you’d like a place to host it.
And a last minute addition as I’m almost done writing this post, Pacific Spatial Solutions translated a ton of Tokyo building and risk data into GeoParquet, you can find it in the list of data in their github repo.
What’s next
So I think we’ve made a really great start on a robust ecosystem. But our goal should be to go much, much further. I believe GeoParquet is fundamentally a better format than the other geospatial formats. But just having great properties as a format doesn’t necessarily mean it’ll be widely adopted. The goal for the next couple of years should be to have GeoParquet be ubiquitous. Every piece of software that understands geospatial data should support the standard. And ideally, it’s the preferred geospatial format of tools that are just starting to support geospatial.
But I believe the real way to measure its success is by the amount of data you can access in it. We can get the ball rolling by putting tons of valuable data up on Source Cooperative. But to really build momentum we need to evangelize to all data providers, especially governments, to provide their data in this format. So if you’re a provider of data please try to make your data available as GeoParquet, and advocate to your software providers to support it. If you’re a developer of geospatial software please consider supporting the format. And if you’re a data user then advocate to your software and data providers, and start saving your data in GeoParquet.
If you want to help out in building the ecosystem but are having trouble prioritizing it, we’ve got money to help. The OGC will put out a Call for Proposals very soon, asking for submissions to enhance the GeoParquet ecosystem. So if you’ve got a library you want to build, a piece of software you want to enhance to read and write GeoParquet, or some data you want to convert and make widely available as GeoParquet then keep an eye out for it and apply.
There are also a lot of really exciting things coming up for the evolution of GeoParquet, that I think will take it from a format that’s better in many little ways to enabling some things that just aren’t possible with today’s geospatial formats. But that’s a topic for future blog posts. For now, I just want to thank everyone who’s been early in support of GeoParquet — it’s been a great community to collaborate with, and it feels like we’re on the verge of something really exciting. And if you’d like to join the growing community, we just started a #geoparquet channel on the Cloud Native-Geospatial Foundation slack (click the link to join). And if you’d like to join our community meetings (17:00 UTC time, every other week) then sign up for this google group and you should be added to the calendar (we have no plans to actually use the forum — use slack instead).
Our blog is open source. You can suggest edits on GitHub.