Sharing Some Tools for Working with GeoParquet
A goal for me this year is to ‘ship more’, so in the spirit of releasing early and often I wanted to share a little new project I got going this past weekend. See https://github.com/cholmes/geoparquet-tools.
It’s a collection of utilities for things I often want to do but that aren’t trivial out of the box with DuckDB. It started focused on just checking GeoParquet files for ‘best practices’, which I’ve been working on writing up in this pull request, as I realized that lots of people are publishing awesome data as GeoParquet but don’t always pick the best options (and the tools don’t always set the best defaults). So it can check compression, if there’s a bbox column, and row group size. It also attempts to check if a file is spatially ordered, but I’m not sure if it works across different types of approaches. It does seem to work with Hilbert curves generated from DuckDB.
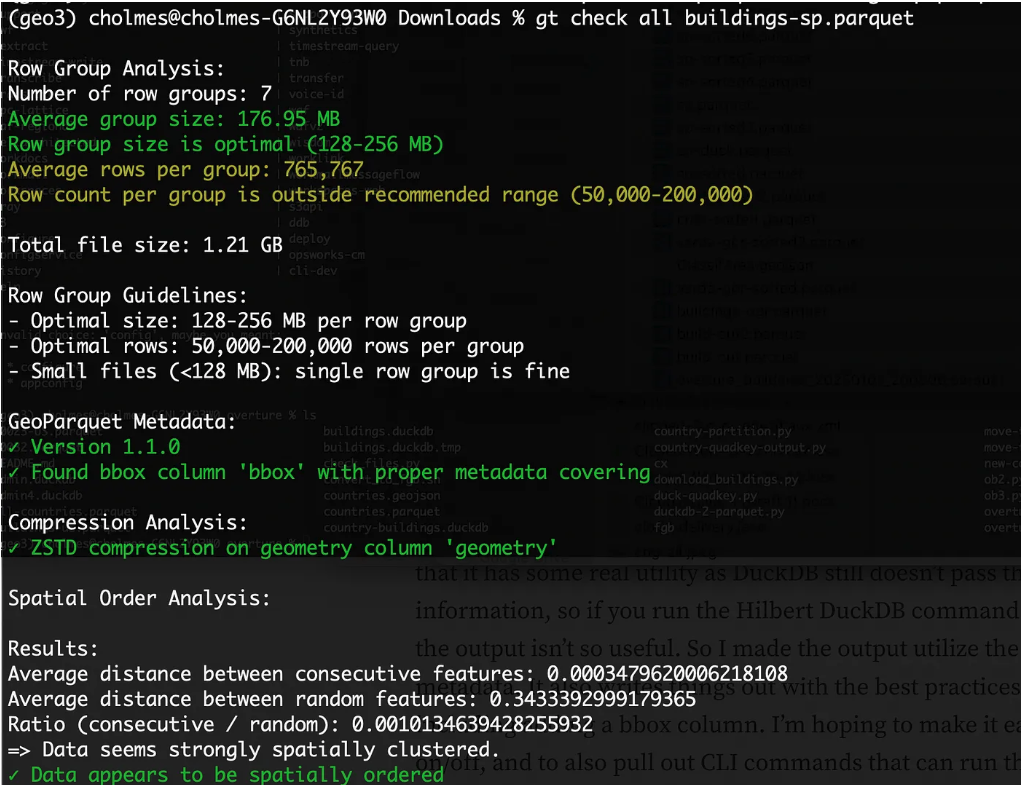
I do need to refine the row group reporting a bit — I think the row group size in bytes is more important than the number of row groups, but I want to try to gather more information about what’s optimal there.
From there I made a utility to do the Hilbert ordering that DuckDB can do. This was initially just for conveinence, so I could just make a one line call instead of remembering the complex SQL statement. But then I realized that it has some real utility as DuckDB still doesn’t pass through projection information, so if you run the Hilbert DuckDB command on projected data the output isn’t so useful. So I made the output utilize the input parquet metadata. It also writes things out with the best practices I’m checking for, including adding a bbox column. I’m hoping to make it easier to turn that on/off, and to also pull out CLI commands that can run the full formatting or any part of it, but it’s proven a bit trickier than I was hoping.
The other main functionality I was to make it easier to create the ‘admin-partitioned’ GeoParquet distributions that I blogged about awhile ago. I got excited about these, but then they didn’t seem to go anywhere. But I think there are some places it can be quite nice, and I want to try it on this Planet dataset of ML generated field boundaries for all of Europe. So I decided to build a utility that’s a bit more generic.
Matthias Mohr and Ivor Bosloper put together this great administrative division extension for fiboa:
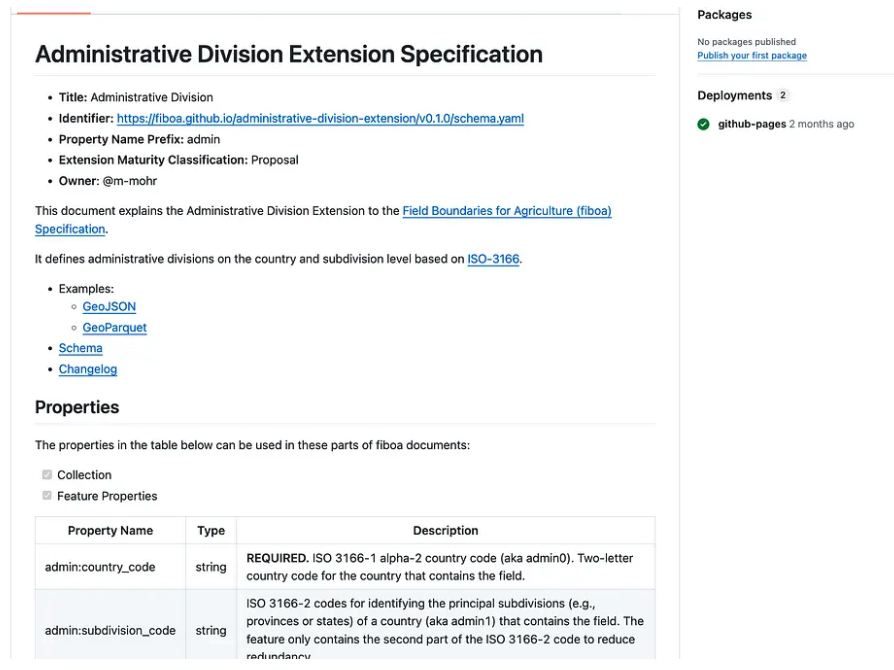
I’ve been thinking a lot about pulling things out of fiboa / STAC to just be a part of the general GeoParquet ecosystem, and this one seems like a perfect one to start with. It has a real practical utility, as once you add these codes you can then split your files by them to partition them spatially.
I did it as two commands, one to add the column (gt add admin-divisions) and then one to split based on the column (gt partition admin). It’s just countries for now, but I hope to add subdivision_code. And it’s just based on Overture, but I also hope to make it so the definition of the admin boundaries is flexible and configurable.
My hope is to add more partitions to the CLI, like the ones Dewey discussed in his post on Partitioning strategies for bigger than memory spatial data. And also hoping to get in more ‘sort’ options as well, and also expand the gt add sub-command to perhaps add h3, s2, geohash, etc. and to also add the bounding box column to any file (I built it into the hilbert sort, so just need to get it fully working and extract it out).
I was hoping to get to create my own first proper pypi package so I could let people pip install geoparquet-tools, but I ran out of time for this round. I hope to do it soon, and to also add proper tests. And then my further hope is to also distribute at least a subset of this functionality as a QGIS plugin, and/or incorporate in my geoparquet downloader plugin, so people can easily check out how well remote parquet files follow the best practices.
Our blog is open source. You can suggest edits on GitHub.